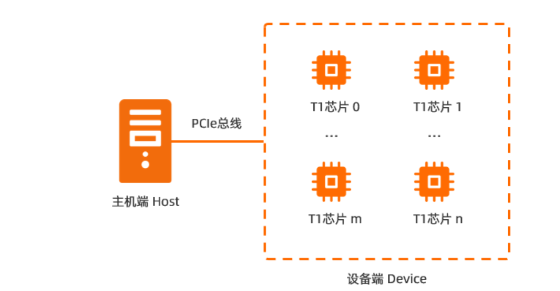
Teco异构并行计算平台

Teco异构并行模型采用主从异构的物理架构,即Host-Device运行模式。
SPMD于SDAA C
SPMD(Single Program Multiple Data,单程序多数据),是一种用于任务并行的编程范式。其本质是将一个问题分解成若干个子问题,然后对其并行求解。
SDAA C编程模型遵循SPMD编程范式,同一计算核心阵列SPA内所有计算核心SPE运行同一份应用程序,每个SPE可以独立完成对子问题的并行求解。其核心在于对复杂计算任务的切分,并合理地将计算任务分配到不同的SPE内进行计算。
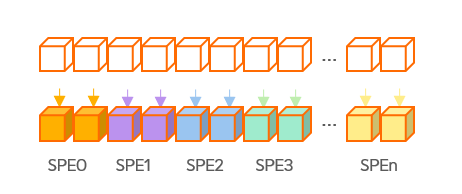
SDAA C编程模型提供了threadIdx和threadDim为每个SPE定制计算任务。其中:
编程示例
以数组计算为例,将计算任务分配到同一SPA的所有SPE内并行执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| using namespace sdaa;
#define SIZE 67
__device__ int g_data[SIZE];
__global__ void func()
{
// 初始化原始数据
for (int i = 0; i < SIZE; i++) {
g_data[i] = i;
}
// SPE同步,确保所有的SPE都完成了数据的初始化
sync_threads();
// 可用的计算资源超过计算量时,每个SPE承担一次计算
if (threadDim >= SIZE) {
if (threadIdx < SIZE) {
g_data[threadIdx]++;
}
} else {
// 可用计算资源少于计算量时,每个SPE需承担多次计算
// 例如当前计算量为67,假如共有32个SPE参与计算。则每个SPE需要至少承担两次计算任务
int cal_time = SIZE / threadDim;
for (int i = 0; i < cal_time; i++) {
g_data[i * threadDim + threadIdx]++;
}
// 对于剩余的计算量使用部分SPE承担
// 例如当前的计算量为67,共有32个SPE参与计算,每个SPE计算两次后,还剩余3次。则使用0, 1, 2三个SPE完成剩余的计算任务
int remain_time = SIZE % threadDim;
if ((threadIdx + 1) <= remain_time) {
g_data[cal_time * threadDim + threadIdx]++;
}
}
// SPE同步,确保所有的SPE都完成了子问题的求解
sync_threads();
// 打印输出计算结果
for (int i = 0; i < SIZE; i++) {
printf("SPE ID = %lu, g_data[%d] = %d\n", threadIdx, i, g_data[i]);
}
}
|
上述应用程序中就通过SPMD编程范式完成对复杂任务的求解。
SP(Single Program,单程序):所有参与计算的SPE都执行同一份代码,在本例中为func函数。
MD(Multiple Data,多数据):通过threadIdx将数组进行切分,每个SPE仅需完成少量运算。
在本例中:SIZE为67,假如可用计算资源为32个SPE,计算资源少于计算量,每个SPE需要承担多次计算,如:SPE0需要计算数据g_data[0]、g_data[32]和g_data[64]、SPE1需要计算数据g_data[1]、g_data[33]和g_data[65]等。
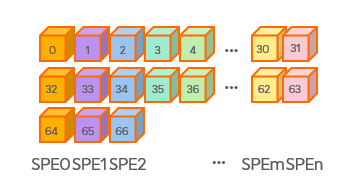
图2 使用SPMD编程范式完成数组计算任务
具体计算任务的代码片段如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 可用计算资源少于计算量时,每个SPE需承担多次计算
// 例如当前计算量为67,共有32个SPE参与计算。则每个SPE需要至少承担两次计算任务
int cal_time = SIZE / threadDim;
for (int i = 0; i < cal_time; i++) {
g_data[i * threadDim + threadIdx]++;
}
// 对于剩余的计算量使用部分SPE承担
// 例如当前的计算量为67,共有32个SPE参与计算,每个SPE计算两次后,还剩余3次。则使用0, 1, 2三个SPE完成剩余的计算任务
int remain_time = SIZE % threadDim;
if ((threadIdx + 1) <= remain_time) {
g_data[cal_time * threadDim + threadIdx]++;
}
|
代码中涉及部分关键字含义如下: